Table of Contents
1. Introduction
Transition-based dependency parsers are a type of popular tool for solving structured prediction problems or joint prediction problems. There are many constructions for transition-based dependency parsers such as transition systems, feature engineering, neural-network predictors and the importance of training against a “dynamic oracle.” In short, those methods rely on the heuristic learning strategies.
In contrast to previous approaches, in this paper, they focus on building dependency parsers which have a compiler can automatically translate a simple specification of dependency parsing and labeled data into machine learning updates. In this way, dependency parsers can use machine learning technology to get more accuracy in complex prediction problems.
The credit assignment is an issue in complex prediction problems. There are two common ways:
- The system may ignore the possibility that a previous prediction may have been wrong. Alternatively, ignore that different errors may have different costs (consequences). Alternatively, that train-time prediction may differ from the test-time prediction. These and other issues lead to statistical inconsistency: when features are not rich enough for perfect prediction the machine learning may converge suboptimally.
- The system may use handcrafted credit assignment heuristics to cope with errors the underlying algorithm makes and the long-term outcomes of decisions.
For some applications, for example, the dependency parsing, it can be much more complicated if applying two strategies.
In the paper, they show a learning to search compiler (or credit assignment compiler) can handle credit assignment when applied to dependency parsing. Moreover, the advantages are as follows:
- The system automatically employs a cost sensitive learning algorithm instead of a multiclass learning algorithm, ensuring the model learns to avoid compounding errors.
- The system automatically “rolls in” with the learned policy and “rolls out” the dynamic oracle insuring competition with the oracle.
- Advanced machine learning techniques or optimization strategies are enabled with command-line flags with no additional implementation overhead, such as neural networks or “fancy” online learning.
- The implementation is future-friendly: future compilers may yield a better parser.
- Train/test asynchrony bugs are removed. Essentially, you only write the test-time “decoder” and the oracle.
- The implementation is simple: This one is about 300 lines of C++ code.
To sum up, the author explains the system in four parts: introducing solve structured prediction tasks using learning to search, implementing learning to search to solve dependency parsing, experimental result, and related work.
2. Learning to search
Learning to search is a family of approaches for solving structured prediction problems or joint prediction problems. Learning to search includes many algorithms such as the incremental structured perceptron, SEARN, DAGGER, AGGREVATE, and others. On the whole, these algorithms have the similar framework, but their difference are in the rollin/rollout policy and the base learner.
In this paper, they build an efficient framework using imperative learning to search, in figure 1. In the framework, it includes:
- a “decoder” for the target structured prediction task (e.g., dependency parsing),
- an annotation in the decoder that computes losses on the training data,
- a reference policy on the training data that returns at any prediction point a “suggestion” as to an excellent action to take in that state.
To fully understand this proposed framework, we need back to the concept of the learning to search.
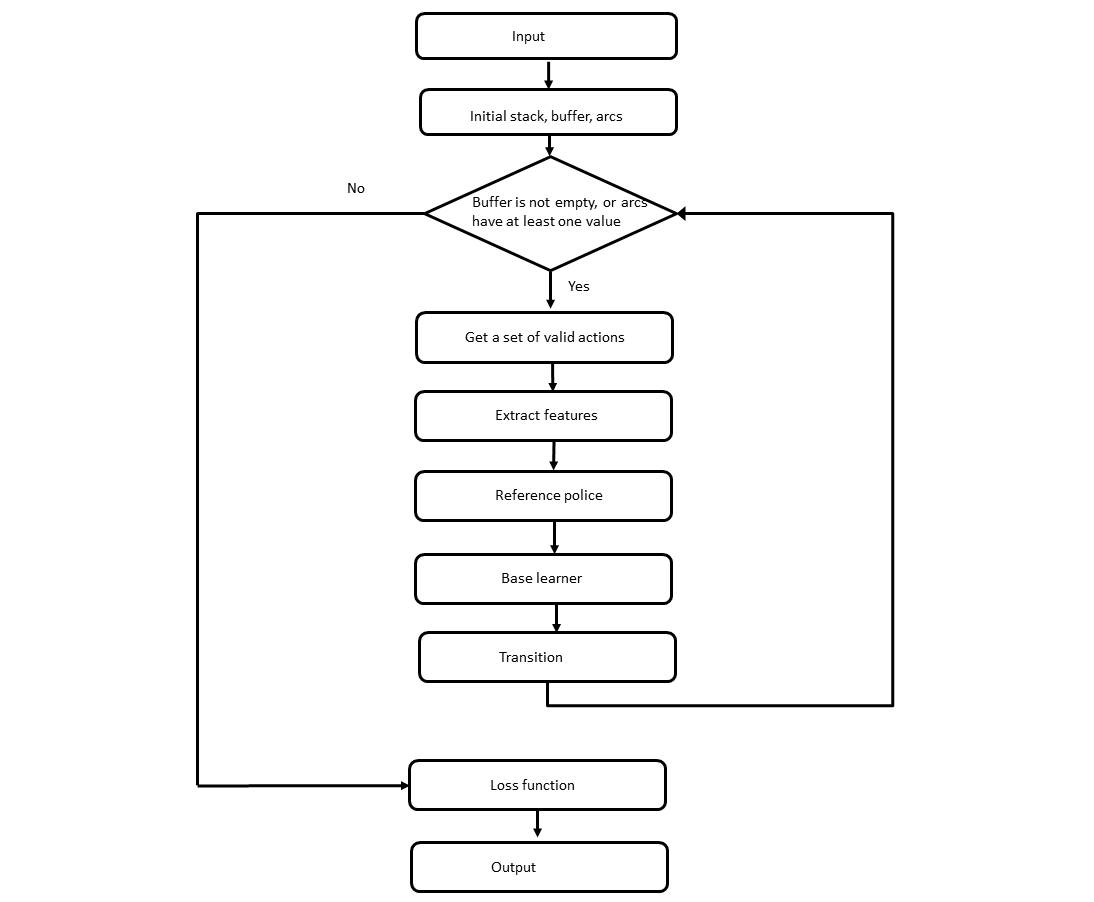
The workflow of the proposed framework.
Learning to search approaches solve structured prediction problems by (1) decomposing the production of the structured output regarding a specific search space (states, actions); and (2) learning hypotheses that control policy that takes actions in this search space. Figure 2 provides an example to illustrate the learning to search approach. In this example, it executes the program three times and able to explore three different trajectories and compute their losses. The rollin policy determines the initial trajectory, the state R is the position of one-step deviations and the rollout policy is to complete the trajectory after a deviation. In brief, the learning to search first follows the learned policy to finds different predictions from the base learner, yields low Hamming loss and gets the reference policy.
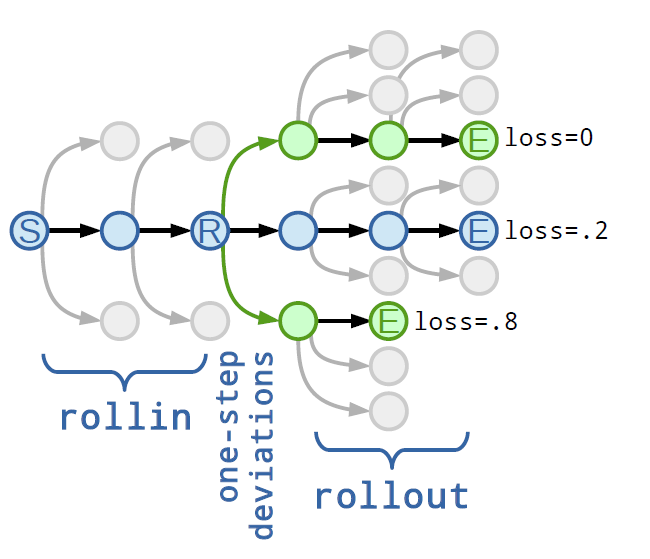
A schematic of the search space implicitly defined by an imperative program.
By varying the rollin/rollout policy and base learner, it can come up different algorithms. In this paper, their rollin=mixture of the learned and the reference (dynamic oracle) policies and rollout=reference (dynamic oracle) policy, and their base learner has varied options. In contrast, DAGGER uses the rollin=learned policy and the rollout=reference policy, and SEARN uses the rollin=rollout=stochastic mixture of learned and reference policies. Next, we will explore the implementation of the learning to search to solve dependency parsing.
3. Dependency Parsing by Learning to Search
A transition-based dependency parser takes a sequence of actions and parses a sentence from left to right by maintaining a stack S, a buffer B, and a set of dependency arcs. An example in figure 3 whos a processing. To classify transition-based dependency parsers, we can learn from three aspects which are the transition system, the base learner, and the reference policy. There are three primary transition systems: arc-standard, arc-eager, arc-hybrid. For the base learner, it can be diverse such as perceptron, natural network, and SGD. As for the reference policy, there are greedy, beam search, and dynamic oracles.
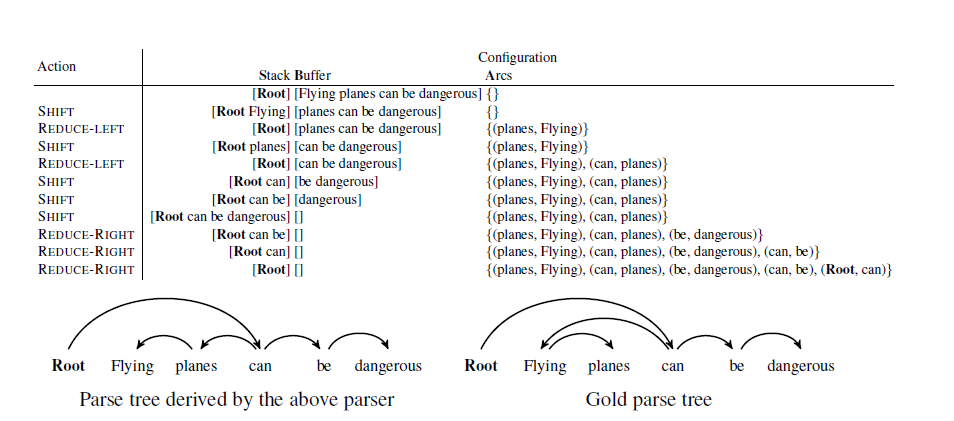
An illustrative example of an arc-hybrid transition parser.
In this paper, they use arc-hybrid for the transition system, the natural network for the base learner (also try more powerful base learners), and dynamic oracles for the reference policy. The arc-hybrid includes three actions: SHIFT, REDUCE, and REDUCE-RIGHT. For others transition system, those have more actions than arc-hybrid. The fundamental principle of dynamic oracles is that for some transition systems there is more than one path that could lead to the gold tree. In contrast, for greedy parsing, we are only considering one of them, which is the one determined by the deterministic oracle. In short, all frameworks are similar as discussed in section 2, but the implementation can be much more comfortable.
In section 2, to implement a parser using the learning to search framework, we need to provide a decoder, a loss function, and reference policy. Therefore, the author provides six functions:
- GETVALIDACTION returns a set of valid actions that can be taken based on the current configuration.
- GETFEAT extracts features based on the current configuration.
- GETGOLDACTION implements the dynamic Oracle
- PREDICT is a library call implemented in the learning to search system.
- TRANS function implements the hybrid-arc transition system.
- LOSS function is used to measure the distance between the predicted output and the gold annotation.
To notice that, there are two LOSS functions, one for unlabeled dependency parser and other for labeled dependency parser.
Compare with other implementation, the learning to search compiler have two advantages for implementation: First, in the learning to search framework, there is no need to implement a learning algorithm. Second, learning to search provides a unified framework, which allows the library to serve common functions for ease of implementation.
4. Experimental Results
Experiments on standard English Penn Treebank and nine other languages from CoNLL-X show that the compiled parser is competitive with recently published results (see figure 4 and figure 5).
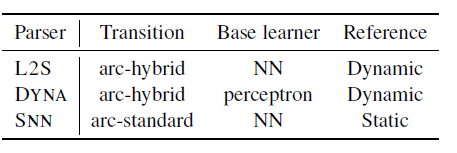
Parser settings.
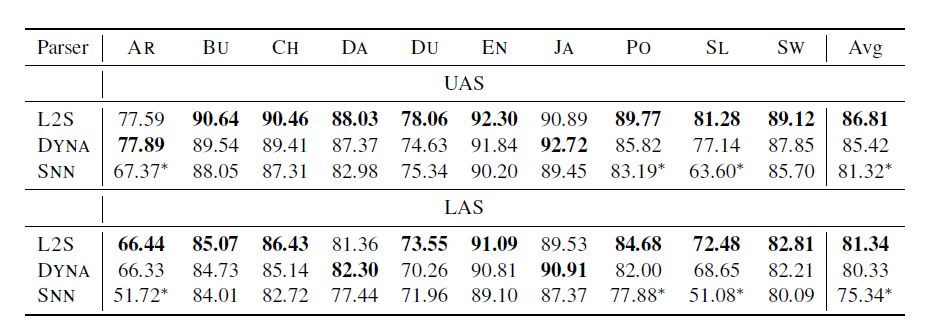
Unlabeled attachment scores (UAS) and labeled attachment scores (LAS).
5. Related Works
Some works use the learning to search approach to solve various other structured prediction problems, but these works are a unique setting under author’s unified learning framework. In conclusion, the learning to search compiler is the first work that develops a general programming interface for dependency parsing, or more broadly, for structured prediction.
Reference
- Kai-Wei Chang, He He, Hal Daume III, and John Langford. 2015a. Learning to Search for Dependencies. arXiv:1503.05615.
- Ballesteros, Miguel. “Transition-based Dependency Parsing.” 2015. PowerPoint presentation